In October, I pointed out that Ann Selzer, Iowa’s Queen of Polling, was so unnaturally good at polling elections that she actually had a better track record of predicting elections than Nate Silver. I therefore introduced the Selzer+Silver model, which aims to improve the FiveThirtyEight model by (basically) treating Selzer’s polls as the absolute truth and using them to anchor the FiveThirtyEight model results.
At the time, my analysis was entirely retrospective and therefore could have been caused by cherry-picking results. As I said then, “there are many pollsters and one of them has to be the best.”
Now that the 2022 elections have come and gone, we can extend our analysis forward and see how the Selzer+Silver performed.
Selzer & Co. polling performance
First, we can look at how accurate Selzer & Co. polls were relative to the actual result. And as always, her polls were extremely accurate. She polled two statewide races in Iowa, for Senate and for Governor, and both were within 0.5%:
| year | Election | Republican 2-party vote share | Selzer Final poll |
|---|---|---|---|
| 2022 | Senate | 56.1% | 56.4% (+0.3%) |
| 2022 | Governor | 59.5% | 59.3% (-0.2%) |
That’s two polls that were basically right on the money, one slightly high and one slightly low. No sign of bias and no sign of any out-of-sample error.
If we add these results to our running table looking at all her polls since 2008, she continues to have minimal bias and a lower error than you would expect from a perfect poll of 800 voters.
| Selzer Final Polls | |
|---|---|
| RMSE | 1.72% |
| Mean Bias | -0.6% |
I would like to, once again, point out how incredibly odd this is! Ann Selzer seems to be the only pollster in the country that isn’t affected by out-of-sample bias or education polarization and who basically doesn’t have a “house effect”. Basically, she seems to be the only pollster whose results and margins of error you can take at face value. And I would very much like to figure out what makes this possible! There doesn’t seem to be anything special about her technique. She’s fairly transparent about her methodology and has given tons of interviews where she’s been asked about her “secret sauce” and there just doesn’t seem to be one. Call people using random digit dialing, weight by “age, sex, and congressional district”, do nothing else, and report the results no matter what they are. And yet no one else seems to come close to matching her!
Selzer+Silver model performance
Second, how did my Selzer+Silver model perform compared to the base FiveThirtyEight model? Back in my October post, I made the following predictions:
The Selzer+Silver model will have a lower Brier score for the 2022 Senate elections than the FiveThirtyEight model, and will more accurately predict the number of House seats won by each party
Unfortunately for my hypothesis testing, the Selzer+Silver model and the FiveThirtyEight model had basically identical predictions. The Selzer+Silver model gave the Democrats a 40% chance of winning the Senate and a 13% chance of winning the House, and FiveThirtyEight said their chances were 41% and 16%. And the reason that the models were so close together is that FiveThirtyEight thought Chuck Grassley would win re-election in Iowa with 56.4% of the vote, and the final Selzer & Co. poll had him winning with 56.38% of the vote. When the Selzer poll is so close to the FiveThirtyEight prediction, treating it as the absolute truth isn’t going to change the forecast much.
But I promised I’d evaluate my claims, so I should go ahead and do that. First, here’s what the two different models predict for the different Senate races:
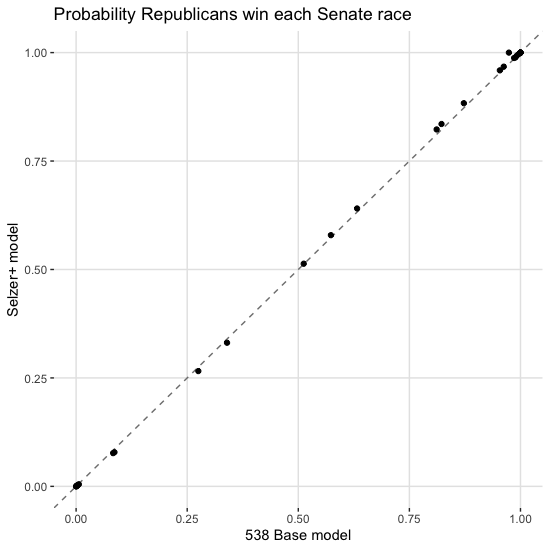
Yeah, the differences between the two models are pretty small. Here’s what the results look like if we look at the difference between the two models:
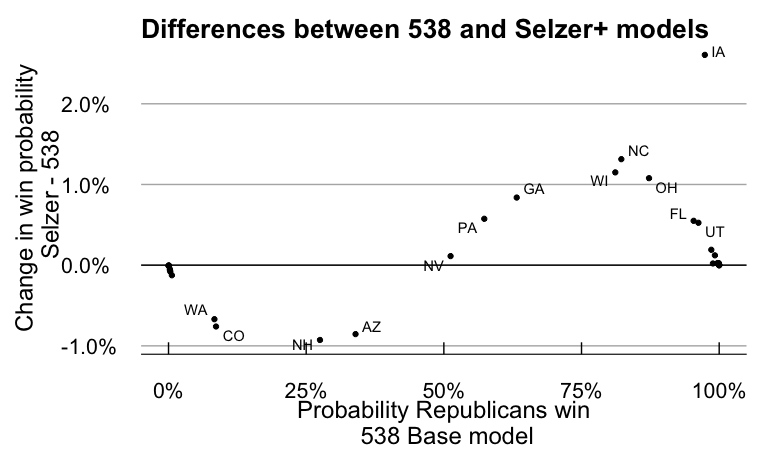
The Selzer+Silver model has slightly smaller error bars than the FiveThirtyEight model, so all the probabilities move towards either 0 or 100, depending on which side of 50% they started on. But the differences are pretty small - the biggest change is in Iowa, where the probability of a Republican win increased by 2.5%.
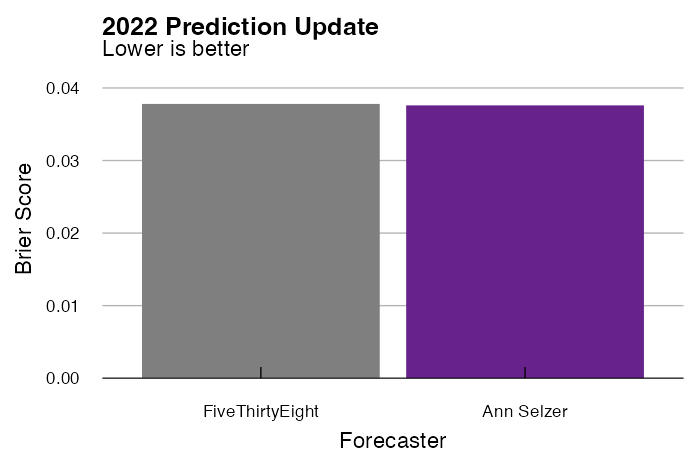
Now we can go ahead and calculate Brier scores for the results. Brier scores are calculated between 0 and 1, where lower scores mean the forecast was more accurate.
| Brier Score | |
|---|---|
| FiveThirtyEight | 0.0378 |
| Selzer+Silver | 0.0376 |
By a hair, the Selzer+Silver model slightly outperforms the FiveThirtyEight model.
We then turn to my second pre-registered analysis, looking at which model will “more accurately predict the number of House seats won by each party”. Now, at the time, that seemed like a very clear analysis. But looking at it now, I think it’s actually a little unclear, since both models generate a range of outcomes, rather than a single point estimate. So I see two ways you could interpret my pre-registered analysis:
- Compare the number of seats won by Republicans to the mean prediction of each model
- Compare the probability each model assigned to number of seats won by Republicans.
That means it’s time for another table:
| Mean number of R seats | Probability of R winning 222 seats | |
|---|---|---|
| FiveThirtyEight | 229.76 (+7.76) | 0.029 |
| Selzer+Silver | 229.64 (+7.64) | 0.032 |
Once again, the Selzer+Silver model ever so slightly outperforms the FiveThirtyEight base model.
Now, while I will take a small victory lap for these results, I’m going to proceed to undercut my own victory.
First, the Selzer+Silver model did not improve the point estimate over the base FiveThirtyEight model. The improvement in the Brier score is tiny and driven by the Selzer+Silver model having smaller tails than the FiveThirtyEight model. And tail behavior isn’t going to reflected in the Brier scores for a single election. By definition, tails don’t matter most of the time, so in most election you’d expect a model with narrower tails to outperform a model with wider tails - but it’s the unusual elections that you really need to worry about. What’s more, there’s already been tons of debate by actual experts about whether the tails on the FiveThirtyEight model are correct or not, so I’m not going to have anything to contribute to the discussion. My hope was that the Selzer+Silver model would improve the point estimate of the FiveThirtyEight model and that wasn’t the case this year. I think the best we can say is that the Selzer+Silver model didn’t make the FiveThirtyEight model worse.
Second, I want to focus on the big picture, which for this election I think was the difference between predictions based on models and predictions based on vibes. For simplicity, I’m just going to look at the probability that different groups gave to Republicans winning the Senate:
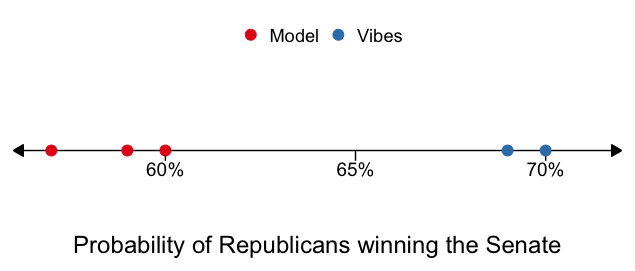
The three models here are FiveThirtyEight, the Economist, and Selzer+Silver; the two “vibes”-based estimates are from PredictIt and Matthew Yglesias (this isn’t an attempt to dunk on Yglesias, he’s just the only pundit I know of who bothered to put numbers of his predictions). The entire range of outcomes here isn’t huge (57% - 70%), but all of the model predictions did significantly better than the vibes predictions. I’d also hazard that among pundits who didn’t put numbers on their predictions (so, basically all of them), most of them would have given Republicans a greater than 70% of winning the Senate. Which is just to say that for all the grief sent Nate Silver’s way (including from me!), FiveThirtyEight is good at what they do and have improved how we all think about elections. I just think there’s still room to do better.
Conclusions
So, after all that, what have we learned? Unfortunately, I don’t think we’ve learned much about the relative merits of the Selzer+Silver and FiveThirtyEight models. The two predictions were just too similar this election to say anything meaningful about the different approaches. I do think we learned a few things about polling and election predictions though:
- When thinking about elections, the biggest gains come just from having a model. The advantage or disadvantages between the different models are pretty small compared to the advantage you have from having any sort of model.
- Poll weighting and poll averaging is surprisingly hard! Crudely, you have two options for how much weight to give to different polls: you can look at methodology or you can look at past accuracy. I think Trafalgar group is a good example of the dangers of looking only at past accuracy. They were one of the most accurate pollsters in the 2020 elections, even though their methodology is, to put it generously, rather suspect, and in 2022, their polls overestimated Republican support by 7.5%. But I think Selzer & Co. is a good example of the dangers of only looking at methodology. Even though they don’t follow all of the currently standard best practices for polling (e.g., weighting for education), they’ve been the most accurate pollster for the past 20 years.
- Ann Selzer continues to be astoundingly good at predicting elections and I want to know why! Is she actually magic? If she’s not, how come no other pollster can match her performance?
That’s all for the Selzer+Silver model in 2022. I’m hoping to dig more into why Ann Selzer is so good at some point in 2023, but I don’t expect to come up with a satisfying answer when no one else has. Currently my best idea is to see if there are other “Selzer-esque” groups out there - pollsters who only poll one state, but do it very very well. And regardless of what I find, I’ll be hoping for some more Selzer & Co. outlier polls in 2024!